
浅谈TXT2SQL工程实践
编辑
浅谈TXT2SQL工程实践
写在前面:本文是作者参与到企业TXT2SQL项目后,有感而发,仅仅提供思路。不代表行业做法,不一定最优。
假设有以下数据表, 如: table_name=product_item_table:
| ID | PRODUCT_NAME | NUMBERS | PRICES | SHIPMENT | CLICK | T_CLICK | YEAR |
|---|---|---|---|---|---|---|---|
| ITM001 | XIAOMI 7 | 150 | 199.99 | 1250 | 0.085 | 0.072 | 2024 |
| ITM002 | XIAOMI 8PRO | 80 | 599.50 | 820 | 0.102 | 0.095 | 2024 |
| ITM003 | XM ARC 9 AIR | 300 | 89.90 | 2500 | 0.065 | 0.058 | 2024 |
| ITM004 | Redmi APX | 60 | 329.00 | 450 | 0.125 | 0.110 | 2024 |
| ITM005 | Radmi 12PRO | 120 | 219.00 | 980 | 0.092 | 0.084 | 2024 |
是什么
近年,LLM发展迅速,但是存在知识不可更新问题,因此出现了RAG,根据输入的query,在知识库搜寻相似度高内容,提供给LLM问答。
由于数据表(csv)此类数据难以很好嵌入到向量数据库。因此RAG又分为了向量数据库召回型与SQL关系型数据库召回型。
从而有了根据自然语言输入,到大模型生成SQL查询语句,执行SQL语句返回结果作为上下文输入大模型,进行问答
探索
Prompt Enginner
在刚拿到这个项目之时,我想了一个最小的MVP的方法,直接使用prompt引导模型(qwen 32b)输出。准确率一般。
其问题出现在:
1.LLM处理复杂问题生成sql效果不好 ()
2.LLM不理解query的token。基于不准确的关键词会生成不准确的sql (在)
3.LLM对于多个陌生词堆叠难以判别其分词 (XM ARC 9 AIR会判断为两个实体)
4.LLM对于模糊词/缩写词的处理效果不好 ("系列/类的产品的平均价格 、 RM的售价",此处模型不会定义系列,不明白RM是Redmi)
及其他问题。
究其原因我认为,在于:
- 大模型没见过数据表的内容
- 大模型对自然语言-sql理解不够
因此为了解决这个问题,需要设计其他工程优化。
多环节的Prompt流
以下都是基于Prompt实现的
解决问题 1 :做了问题拆分,将复杂问题拆分为多个简单问题
解决问题 2 :提供数据表的schema、description信息
解决问题 3 :使用分词的方式标定某些字属于一个token
解决问题 4 : 提示使用ilike/构建一个缩写映射表
工作流如下
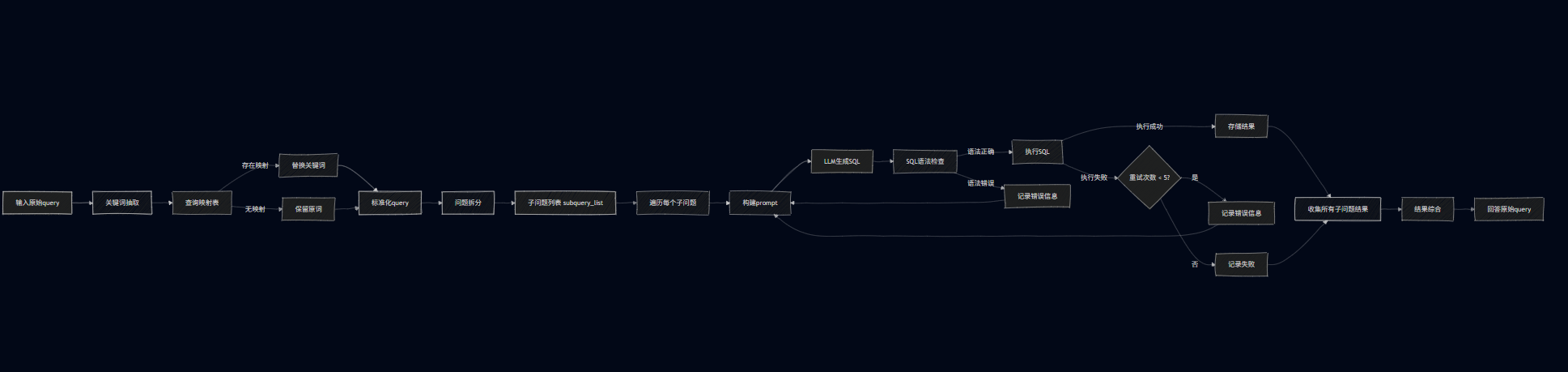
flowchart LR
A[输入原始query] --> B[关键词抽取]
B --> C[查询映射表]
C -->|存在映射| D[替换关键词]
C -->|无映射| E[保留原词]
D --> F[标准化query]
E --> F
F --> G[问题拆分]
G --> H[子问题列表 subquery_list]
H --> I[遍历每个子问题]
I --> J[构建prompt]
J --> K["LLM生成SQL"]
K --> L[SQL语法检查]
L -->|语法正确| M[执行SQL]
L -->|语法错误| N[记录错误信息]
N --> J
M -->|执行成功| O[存储结果]
M -->|执行失败| P{重试次数 < 5?}
P -->|是| Q[记录错误信息]
Q --> J
P -->|否| R[记录失败]
O --> S[收集所有子问题结果]
R --> S
S --> T[结果综合]
T --> U[回答原始query]
基于微调的探索
实际上基于prompt的软规范不能保证准确性。且一直没有解决"大模型没见过数据表的内容"的问题
因此我们尝试了微调的方法。分别使用在了三阶段
在此阶段,我期望大模型除了学习指令跟随的格式,更重要的是记住数据表的内容,增加知识。
1.分词
2.子问题拆分
3.SQL模型微调
数据构造
基于原有数据表字段,人工编写了900+模板,此模板用于填充数据表的数据来构建问题、分词结果、SQL查询数据、子问题拆分
数据均基于模板填充,1key~5key的比例为 1:2:3:2:1,此处考虑到3key的情况比较多。
tempalte:{P}在2024年的商品销量是多少?
#随机按比例填充
Query: Radmi 12PRO在2024与2025年的商品销量是多少?
key:Radmi 12PRO|2024|2025|SHIPMENT
SubQuery: ["Radmi 12PRO在2024年的商品销量是多少?","Radmi 12PRO在2025年的商品销量是多少?"]
SQL: ["SELECT YEAR,SUM(NUMBERS) AS TOTAL_SALES FROM xxx WHERE PRODUCT_NAME = 'Radmi 12PRO'AND YEAR="2024" GROUP BY YEAR;",
"SELECT YEAR,SUM(NUMBERS) AS TOTAL_SALES FROM xxx WHERE PRODUCT_NAME = 'Radmi 12PRO'AND YEAR="2024" GROUP BY YEAR;"]
得到类似数据:
{
"instruction":"你是以一个SQL数据专家,你的任务是xxx,请按照xxx格式输出:"
"input":"Radmi 12PRO在2024与2025年的商品销量是多少?"
"label":"Radmi 12PRO|2024|2025|SHIPMENT"
}
{
"instruction":"你是以一个SQL数据专家,你的任务是xxx,请按照xxx格式输出:"
"input":"Radmi 12PRO在2024与2025年的商品销量是多少?"
"label":"['Radmi 12PRO在2024年的商品销量是多少?','Radmi 12PRO在2025年的商品销量是多少?']"
}
{
"instruction":"你是以一个SQL数据专家,你的任务是xxx,请按照xxx格式输出:"
"input":"Radmi 12PRO在2024与2025年的商品销量是多少?"
"label":"["SELECT YEAR,SUM(NUMBERS) AS TOTAL_SALES FROM xxx WHERE PRODUCT_NAME = 'Radmi 12PRO'AND YEAR="2024" GROUP BY YEAR;","SELECT YEAR,SUM(NUMBERS) AS TOTAL_SALES FROM xxx WHERE PRODUCT_NAME = 'Radmi 12PRO'AND YEAR="2024" GROUP BY YEAR;"]"
}
参数
| 分词数据 | 子拆分数据 | SQL数据 | 框架 | 显卡 | rank | alpha | 时间 |
|---|---|---|---|---|---|---|---|
| 150k | llamfactory | 8* | 8 | 16 | 8h |
基于向量/字符频率的RAG再度优化
当我做到此处,问题已经比较少了。不过我关注到几个问题。
1.关于缩写/模糊词的匹配。
目前采用的时xlsl表的映射。穷举的方法,但是很难去cover 100%的内容。所以我最后采用向量召回相似key来进行匹配的方式。
- 构建一个json字典的映射,索引为sql表的所有表“字段”、去重后的“值”内容。对应为该索引的解释。
{"Redmi APX":"Redmi APX是PRODUCT_NAMED的一个值","PRODUCT_NAMED":"PRODUCT_NAMED是表的字段,表示产品名"}
- 通过输入query的提取的key_list。来匹配
- 使用"维利塔距离"与"余弦相似度+rerank(bge)"来匹配top_1。
- 最后全部作为参考消息给到LLM做SQL生成。
这样就实现了 从 rm/radmi 匹配到 Redmi。不过这里使用维利塔距离是最合理的,时间是向量匹配是基于语义信息。这种情况的不存在什么语义
效果如何
BTW 了解效果
1.对于可以精准提问的query 99%
2.可解决 query存在字符错误的问题
3.可解决 query系列/模糊词/缩写词的问题
4.可基本解决 query复杂问题
可观测/进一步的idea
以下为个人观点,主题是配置Python环境,让大模型写python代码
针对时间成本
若有n个子问题,最少查询n词,最多5n词。时间成本开销是很大的。
我觉得可以在最后sql执行时候,对其进行SQL语句合并。这样时间就变为1。具体工程不详述。
针对复杂数学指标
目前大多是情况只涉及到了简单的查询,甚至没有进行复杂的数学指标的运算。
如果未来出现,我认为可以使用math的库。基于之前的所有步骤,把最后的SQL结果,让大模型编写Python。提取数据,构建math计算公式。
针对可视化的数据指标
如果我是用户,我更想看到一个饼状图/柱状图/曲线图。来观测趋势、增减、占比。会更加直观。
这个思路让我做也会是直接实现python代码运行。
总结
没什么好说的了我准备离职了,有趣的一次经历。但愿项目越做越好,祝顺利!

- 0
- 0
-
分享