
有关transformer那些事两篇文章带你弄懂一
编辑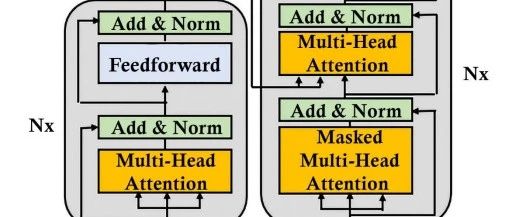
有关transformer那些事,两篇文章带你弄懂!(一)
transformer架构
先上图:
左半部分为输入分词向量嵌入层、N个Encoder
右边部分为当前位置输入层、N个Decoder、线性映射层
transformer架构中的数据流
tokenizer + position encoding
这一部分在上一篇文章已将讲过了:
encoder
多头自注意力子层
设定:
- 向量维度为d_model=4
- Wq\Wk\Wv为(4,3),d_k=3
多头子注意力子层的作用是让模型能够同时关注输入序列中的不同位置,从而更好地理解输入序列的语义信息。多头子注意力子层的具体实现如下:
1. 首先,将输入向量X与三个可学习的权重矩阵WQ、WK、WV相乘,得到Q、K、V三个向量。
计算每一个input输入的QKV矩阵
2. 然后,计算Q和K的点积,得到注意力得分。(这里是分别对每一个Q,与K1,K2,K3做乘法,求相似度得分)
3. 接着,将注意力得分进行softmax操作,得到注意力权重。(可以看出Q1,对K2,K3的注意力比例更大)
4. 最后,将注意力权重与V相乘,得到加权后的向量。
5. 完整流程
6.
这只是一个input得到的注意力值。我们需要多个input进行计算。得到的每一个注意力值的形状为(1,d_k),多个input的结果为(num,d_k)
.
7. 同时一类Wq,Wk,Wv所关注的向量语义维度有限,一般采用多头注意力机制。也就是有多个
Wq,Wk,Wv。结果每一个input会得到多个注意力值(z1,z2,z3...zi),将其拼接起来,多头注意力的结果为(num,d_k * head) 。
8. 同时为了保证输入与输入的形状一致,我们会选择d_k *
head=d_model。也就是如果d_model=512,d_k=64,我们选择8个head.得到的结果唯独就是(num,512),与输入一致。
9. 进行残差与规范化,这里包含两个部分。相加函数与层规范化函数。
LayerNormalization( x + Sublayer(x) )
-
相加函数是一个残差连接。目的是保证关键信息不会丢失(避免梯度消失或者爆炸)。
-
层规范化可以优化数据分布,依次提高模型的训练速度和精度,使得模型更加稳健
- 前馈神经网络子层。这里的FFN是全连接的神经网络。包含两个隐藏层。并且应用ReLU激活函数。
函数如下:
FFN(x)=MAX(0, x*W1 + b1) W2 + b2
decoder
请见下一篇!
predict next token
请见下一篇!请见下一篇!请见下一篇!
transformer的延申
请见下一篇!
后续文章:
- 《从零手撕Bert模型的预训练》
- 《从零手撕GPT模型的预训练》
- 《从零手撕T5模型的预训练》
期待一下吧!!
- 0
- 0
-
分享